Overview
Some academics still consider the placebo model of neurofeedback to be a hurdle to overcome. At this point I question whether to even take up this issue, because as far as we are concerned these people are beating a dead horse. It honors the question too greatly even to discuss it once again. The appearance of the paper last year titled “The Fallacy of Sham-Controlled Neurofeedback Trials 2018,” by Cannon, Pigott, and Trullinger shifts the balance of the argument because it rests on assumptions about neurofeedback that are themselves questionable. Taking up this topic then serves as a springboard to call the entire operant conditioning model of neurofeedback into question, and to propose the more inclusive model of associative learning. We navigate this labyrinth step by step.
On the unsuitability of sham training as a placebo control
To indict the use of sham-controlled studies, the authors rely on two arguments, basically. The first is that sham training is not a neutral condition, and is therefore unsuitable as a control. Sham training calls upon attentional resources under challenge conditions in its execution, and when that is carried on for hours and hours, it should be no surprise that there may be beneficial effects on attentional skills. The same was observed when an ordinary Pacman game was used as a control condition in an early research study involving our NeuroCybernetics. The participants playing ordinary Pacman benefited also from the experience. This argument should suffice to seal the fate of sham training all by itself. The assumption of a ‘non-active’ control is violated—at least when attentional control and executive function are themselves at issue. (It might well be ok if one were targeting migraines or asthma instead.)
However, there is yet another troubling observation to deal with: In the sham-controlled studies cited, the neurofeedback arm is not showing obvious superiority over the sham condition. Bringing to bear fancy instrumentation, along with careful attention to protocol and procedure in order to deliver good feedback on the real-time EEG didn’t really buy much, apparently, over just watching a random EEG in the expectation that it contains relevant information.
The authors wriggle out of this dilemma by arguing that the use of adaptive thresholding compromised the neurofeedback training to the point where it is little better than sham. And here is where we have our differences with the authors, in that we have utilized adaptive thresholding since the early days and it has clearly not been a barrier to good outcomes. More than that, adaptive thresholding has become fairly commonplace in the field over the years. To indict adaptive thresholding calls into question what most people in the field—those who are using these protocols—are doing! That’s shooting ourselves in the foot.
However, it does appear that the adaptive thresholding was not well done in these studies, and that may have contributed to the poor results. In one study, the threshold re-setting was done manually; in another it was done every fifteen seconds; and in another it was done according to an unspecified fuzzy logic paradigm. Nonetheless, this issue cannot be the whole explanation of the poor results. Indeed, there were other problems. One study trained on the theta/beta ratio, which is inherently problematic. Another used instrumentation intended for home use. It had never proven itself in clinical practice.
There was yet another aspect of the design of the studies that deviated from the classic operant conditioning procedure, and yet curiously the authors didn’t call attention to it. This was the reliance on high reward rates of about 80%. This makes no sense in the classical operant conditioning model, in that typical EEG ‘behavior’ of the ADHD child sitting in the chair already qualifies for a reward. What is the incentive to change when the reward signal is telling you nearly all the time, ‘you’re ok…you’re ok…you’re ok’? At high incidence, is a reward still a reward? Neither Sterman nor Lubar thought so; both kept reward incidence low, and believed that aspect to be essential to good training. Further, Sterman was adamant that every reward ought to be followed by a refractory period to allow it to be fully appraised.
The question must be asked just why these authors did not call attention to the most obvious violation of the classical operant conditioning design in support of their argument as to why the neurofeedback arms did not show significant superiority to the sham arms in the published studies. Most likely it is because this tactic has over the years also been widely adopted within the field. Calling it into question would not have been credible–yet another case of shooting ourselves in the foot.
In our early history, once we made the transition to training at a fixed reward incidence via dynamic thresholding, we also determined that moving the reward incidence up from fifty percent gave us much better results. Why start at 50%? That’s the threshold at which the number of crossovers maximizes, so in the information-theory sense it ought to be the most efficient for learning to occur. But that is not what happened. The optimal “percent reward setpoint” kept migrating higher as we gathered clinical experience, and eventually we ended up at levels of 75%, 80%, and even higher in some individual cases. Tethered mentally by theory, we initially resisted the observation, and hesitated to move ever further upward. But the case became compelling over time, and in the end the observation won out, as indeed it should. (Hypothesis precedes data; theory follows it….) Much of the rest of the field followed.
In the above two significant respects (adaptive thresholding and high reward incidence), the published studies largely reflected what the researchers recognized to be standard practice within the field, quite irrespective of the demands of the canonical operant conditioning model. But if these two arguments are taken off the table, we are back to confronting the original question: Why were the results not ‘significantly’ better than sham training? One could cite many reasons. However, I’d like to zero in on two critical differences between our clinical world and the world of research, and these could go a long way to explain why researchers rarely match the results reported by clinicians.
Consider the simple case of hand temperature training biofeedback. If one inserts twenty subjects into the training, and only ten of them demonstrate any kind of ability to raise their finger temperature, then it makes no sense to test all twenty with respect to improvement in headaches, anxiety, insomnia, or whatever the clinical objective may be. That would really foul up the statistics. One can have aspirations for improvement only with respect to the ten who showed evidence of learning having occurred; hence, a valid test of temperature training would have to restrict itself to those who actually acquired some level of control.
How does that translate to the clinical situation in neurofeedback? Our training process differs from temperature biofeedback in that we don’t expect changes in the EEG to reflect the protocol, or to yield early indications of progress being made in the training. That can happen, of course, but it is not the expectation. We have had to take a different approach. We have no alternative but to look for evidence of a response to the training itself, either in terms of induced state shifts (e.g., calmer demeanor), change in functional status (e.g., improved sleep), or of the beginnings of relief with respect to the primary complaints.
Reflecting back on the early days when we were using only a single standard protocol, we were aware that we had only a limited toolkit available. We could not resolve all cases of ADHD. We told parents that if the training was going to be effective, they should begin to see some positive indicators of that within six to ten sessions. If no positive indicators surfaced by that point, they might want to reconsider. The parents would limit their expenditure, and we would maintain our reputation.
At the same time, we also set the expectation that the child might well have to train for forty sessions—even though we re-tested routinely at twenty sessions. Anyone stopping at twenty sessions was cautioned to anticipate the possibility of backsliding. So clinical outcomes were always largely positive by twenty sessions, and even more so by forty, because the non-responders and poor responders were no longer around to be counted. On the other hand, it would not be fair to call those who had abandoned the training at six sessions ‘treatment failures,’ because they hadn’t given the neurofeedback a trial of sufficient duration. We know that some people just take longer to start showing progress with the old protocols. With this approach, the ‘success rate’ is always going to be high, as indeed it has to be in order to sustain a clinical practice.
Now for another anecdote from the annals of biofeedback: The story is told of a situation in which two groups were being training concurrently in thermal biofeedback. One was a group of potential BF practitioners; the other was a group of MDs. The former group succeeded in learning the skill; the MDs largely failed. Once both groups had been apprised of the results, the MDs were given another opportunity to train, and on this occasion they largely succeeded. One surmises that the MDs went into the first training with no expectation of success, and perhaps even with slight embarrassment that they should stoop to involve themselves in such a silly exercise. Only once they had had success demonstrated to them did they shed their skeptical frame of mind.
The clinical setting is all about orienting for success. The research world is all about eliminating any such ‘placebo’ factors. Moreover, the trainees are aware that there is only a 50% chance that they are getting a valid signal to train on. This places them into the same frame of mind as the MDs doing the temperature training. There is no expectation of success. The trainee adopts the same ‘wait-and-see’ attitude as the research staff. There is a wariness, a certain passivity, a posture of challenging the neurofeedback to prove itself. But there is no ‘active ingredient’ in neurofeedback. It’s a learning process, and it obviously makes a difference if one is positively committed to it, particularly with the old protocols.
The practitioner conversant with our current Infra-Low Frequency Neurofeedback training may be wondering at this point about the fact that we routinely train infants, and they are hardly ‘committed to the process.’ Indeed, but they aren’t skeptical, either. The fact is that we worked successfully with infants even with the old protocols, so the process worked even then without the element of volition. The point is that volitional involvement can clearly contribute. That is the implication of the positive outcomes of all that sham training. In essence, we are persuaded that with the old protocols volitional engagement can be additive, and skepticism or resistance can interfere with progress. In the old EEG-band protocols, we are mainly working with the engaged brain; with our ILF protocols, we are training our resting state networks. Volition can play a role in the former; it has no ready way of engaging with the latter.
Finally, we have to contend with the fact that ADHD children are typically not there to solve their own problems. They are there to solve someone else’s problem—that of teachers and/or parents. So if these problems go away, they may not even notice, or care very much. As for the parents, they may not notice either, since they are likely to be ADHD also, and their chaotic home life continues. All of this makes ADHD one of the worst clinical targets with which to demonstrate that neurofeedback is not reducible to placebo, particularly if one relies on such unreliable instruments as parental reports and teacher ratings.
Sealing the Tomb on the Placebo Model of Neurofeedback
What, then, is the answer to this fixation on ADHD by neurofeedback skeptics? Alas, the critics get to choose the battleground. We have to meet them on their turf, and on their terms. So here we go: Neurofeedback is a physiologically based tool. Outcomes should be evaluated with a physiologically-based measure. Such a tool is the continuous performance test (CPT), which also has the benefit of being well-accepted within the field as a diagnostic discriminant and an aid in the titration of stimulant medication. We’ve been using the CPT as a progress measure since 1990. Initially we utilized the TOVA® test, and since 2005 we have used the QIKtest in a mode that emulates the TOVA test design. Since 2013 the QIKtest has had its own norms.
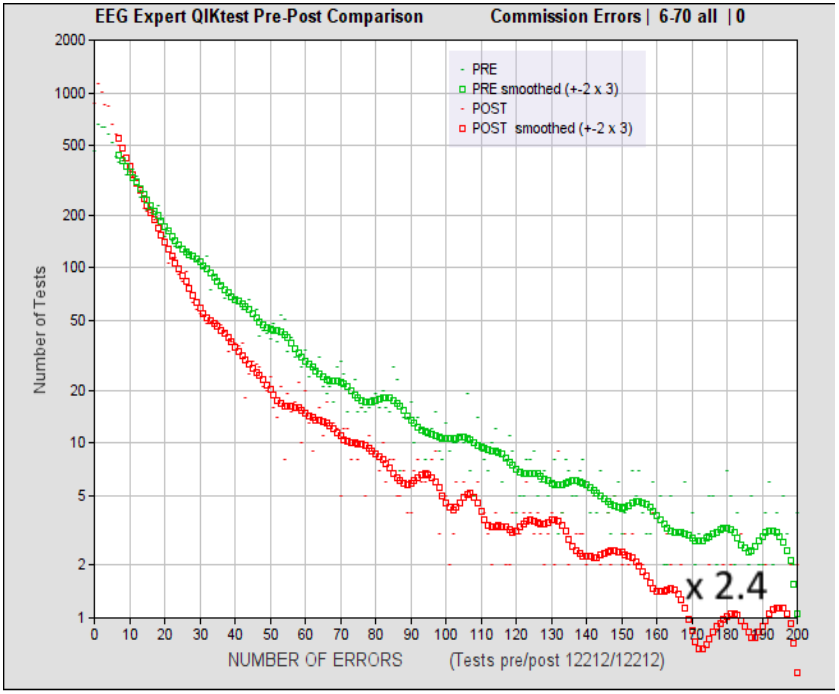
Figure 1. Distribution of incidence of commission errors before and after 20 sessions of Infra-Low Frequency Neurofeedback, for errors up to 200 per test. The number of errors per bin is plotted horizontally, and the number of occurrences for each bin are plotted vertically, on a logarithmic scale. Smoothed data are shown for clarity. The plot reflects the results of 12,212 cases. These were accumulated over a period of more than ten years from contributions of several thousand clinicians utilizing Infra-Low Frequency Neurofeedback protocols for a variety of clinical presentations. Hence they are generally representative of actual clinical practice with paying clients. The Figure dates from 2017.
The results from our practitioner network over the past several years, as acquired with the QIKtest, are shown in Figure 1 for errors of commission. The data show that any measurable level of deficit can benefit from the training. That is to say, anyone capable of taking the test is also capable of benefiting from NF to improve function. Non-responders are found to be relatively rare. Overall, a factor of 2.4 reduction in incidence of commission errors is achieved in the extremes of severe deficit. The data reveal systematic, substantial improvement across the entire domain of functionality. However, in their existing form these data don’t adequately reveal their real-world clinical significance.
For this purpose, we employ our norming data (which was based on over 50,000 records) to assign an equivalent mental age to the median scores of the pre- and post-training cumulative distributions. We also segment the total age range into two developmental phases and a mature period. The developmental phase extends roughly to age twenty; the obvious dividing line of the tenth birthday turns out to be the best choice. It confines the confound of adolescence to the upper age bin. Results for the two developmental age bins are shown in Figure 2 for errors of commission.
Only a fraction of all neurofeedback clients get to take the QIKtest, and only a fraction of those are asked to take a re-test. Many who test well on the pre-test don’t bother with the post-test. This skews the population represented in the figures toward the more deficited end of the distribution. By comparing the mean mental ages of the entire pre-test population with the post-test population, we have been able to demonstrate that the difference in median age is modest (i.e., typically less than a year). That is to say, the above data are largely representative of the entire clinical population that seeks Infra-Low Frequency (ILF) neurofeedback in our practitioner network and gets tested with a CPT.
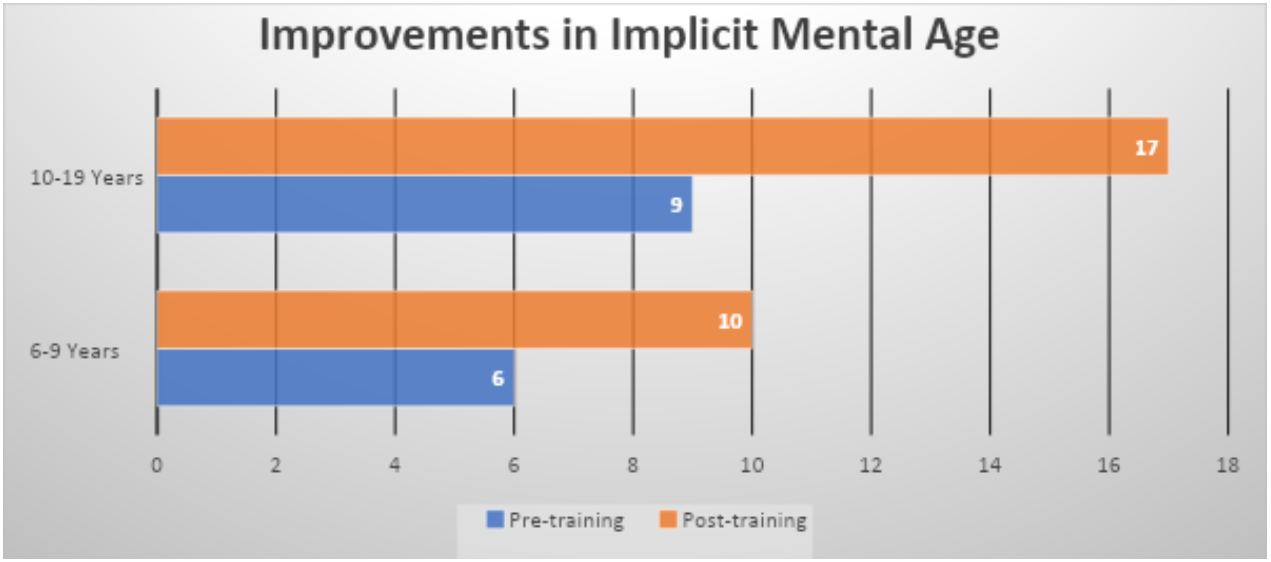
Figure 2. Shown here is the improvement in equivalent mental age for errors of commission, as determined with the QIKtest CPT. The median age is shown for the distributions that cover the entire clinical experience base to date. The 6-9 year cohort includes everyone short of their tenth birthday (2679 cases). The 10-19 year cohort includes people up to their twentieth birthday (5433 cases). These data were acquired in 2017, analyzed in 2018.
Observe that the median equivalent mental age of the younger cohort of 6-10 after 20 sessions of neurofeedback training, namely 10 years, exceeds the pre-training median score of the 10-20-year-old cohort before training, which is only 9 years. So with respect to our measure of impulsivity, the trained 6-10 year-old cohort outperforms the untrained 10-20 year cohort. And we’re only at twenty sessions here, which by no means exhausts the potential of the training process. The more severe the deficit, the more likely that further training will be beneficial.
With thousands of cases at our disposal, and thousands of clinicians involved, these data leave no wiggle room. When clinical improvement is as systematic and as substantial as the data of Figures 1 and 2 indicate, we have a remedy, not a placebo. We are not just demonstrating progress here, but rather systematic functional enhancement beyond age-appropriate norms. With a placebo, the highest expectation would be functional normalization, which in this case would imply a post-training median score of about 8 and 15 years, respectively, for the two age bins. Actual post-training scores exceeded this, and that can be explained only by way of an active training process.
Yet other data demonstrate that this degree of functional enhancement is achieved with only a slight dependence on the severity of the initial deficit. The end point of the process cannot be predicted on the basis of where one starts. No placebo behaves this way. This also means that effect size is not a good index of outcome. The greater the initial deficit in the sample population, the greater the effect size. Functional normalization must be the relevant criterion by which neurofeedback should be judged, and we are achieving even more than that: functional optimization. Stated more correctly, the brain is achieving that objective; we are merely the enablers.
The above considerations prove categorically that neurofeedback is not reducible to placebo. It is an active process of brain training. So we have active processes on all sides. With respect to the objective of enhancing attentional function, sham training is also an active process, as is the playing of video games. All three approaches testify to the proposition that attentional skills can be enhanced by practice among those in whom attentional control is deficient. One must rely on outcome data to establish the actual value of the neurofeedback exercise, and Figures 1 and 2 contribute to that enterprise.
Now if we fold in the results of the studies reviewed in the above paper, we hasten to grant that neurofeedback is aided by placebo factors. It is obviously helpful for the training to be conducted in a success-oriented environment, supported by clinicians who are fully engaged on the mission of client success. This is true of behavioral therapies in general, and it is also true here. As was already said forty years ago (and paraphrasing), “The placebo is not a confounding factor in neurofeedback; it is a compounding factor.”
In our Infra-Low Frequency (ILF) neurofeedback, these compounding factors are baked into the method. The path forward is set on the basis of the trainee’s report during the session, as well as from session to session, so continual engagement with the trainee is part of the process. This interaction serves to enhance the sensitivity of trainees to their own state. We have a learning process on three levels: trainees learn to attend to their own self-regulatory status; the brain learns how to do ILF neurofeedback better over time; and the brain enhances its own self-regulatory competence. If there is no incremental progress, the process grinds to a halt. If there is incremental progress, on the other hand, then that also serves the purpose of increasing commitment to the process—yet another compounding factor.
‘The Placebo Model of Neurofeedback is Dead! Long live the Placebo!’
The main purpose in writing this newsletter has been accomplished. The placebo model of neurofeedback in application to ADHD is dead. However, the issue of the violation of the principles of operant conditioning remains. Starting with the assumption that the rare event is the attended event, one can argue that a kind of role reversal takes place once reinforcement reaches levels of 80% and above. It is the dropout of the rewards that draws the attention. Kids want their rewards back! This all works better when the setpoint of reward incidence is high.
Under conditions of high reward incidence, runs of rewards are interrupted by briefer epochs of few or no rewards. The process has moved from being event-focused (i.e., the discrete reward) to being state-focused (‘strive to persist in the state that elicits a continuous stream of rewards’). The result is an irregular pattern of multi-second intervals, which yields a spectrum that falls into the infra-low frequency range. With the benefit of hindsight, we can now speculatively view SMR-beta training—as it evolved clinically at our hands quite early in our neurofeedback career—as the first instantiation of an element of infra-low frequency training! The high reinforcement rate was mandated in first instance by the frustration tolerance of the ADHD child, but it could also have been driven by the need (unbeknownst to us at the time) of optimizing the sensitivity to the ILF fluctuations in the signal, which depended on making the dropouts the attended event.
This model allows us to make sense of an early case of near-drowning of a 2-year-old child who responded strongly to beta training in the very first session. And yet she was not even watching the signal, as there was no eye-tracking ability. The girl was responding strictly to the ebb and flow of beeps. This case was a challenge to our understanding for many years. We now realize that this was effectively a case of infra-low frequency training–for which single-session effects are commonplace.
It is also useful at this juncture to observe that whereas the ‘event-focus’ of Sterman’s operant conditioning of the cats was appropriate, given the observation of discrete SMR-bursts, the applicability of that same method to humans is not self-evidently optimal. The human EEG is not characterized by discrete SMR-bursts except during stage-two sleep. One can go further. The eventual outcome of extended training of the cats was a near continuous stream of elevated (i.e, bursting) SMR amplitudes in the cats under conditions of reinforcement. A substantial state shift was being maintained. These observations make a shift from an event-focus to a state-focus both appropriate and appealing when it comes to training human brains.
From Operant Conditioning to Associative Learning
We’re not in Kansas anymore. This is no longer operant conditioning in the Skinnerian mold. This is an exemplar of a process of associative learning, of the brain taking information from wherever it is available, all in the service of its core mission of self-regulation. The information from the infra-slow frequency range was available, but it was there without any reinforcement, without anything calling attention to it. Associative learning depends only upon the brain’s discernment of a correlation, and that can occur not only with discrete events but with continuous signals. When the signal at issue relates to brain self-regulation, salience of the signal is not in question. The brain is preferentially attentive to information from the environment that bears on its own activity. As soon as that recognition of correlation occurs, the signal becomes an action item for the brain. This is closed-loop, continuous feedback. It is a matter of the brain engaging with itself, feasting on information it never had available before. The clinician is no longer in charge of the particulars of this process.
The children’s brains shaped clinician behavior over time in the service of their own cause. High reward incidence and a touch of infra-low frequency training was the result. At the same time, SMR and beta frequencies continued to play their own respective roles in the training, modulating activation and excitability. But here as well, it is the dynamics that matter most—in the service of associative learning. Even as we pledged fealty to the operant conditioning model over the early years, along with everyone else, the accelerant in our training had been the aspect of associative learning all along. At some point, the increased sensitivity afforded by associative learning revealed a frequency specificity in SMR-beta training that allowed Sue Othmer to discover the principle of the Optimal Response Frequency (ORF). (It may be noted that if the placebo model of NF weren’t already dead, the existence of ORFs would certainly dispatch it.)
It was quite early on that Joel Lubar vented his exasperation by exclaiming that fast responses to EEG neurofeedback, i.e. demonstrable results within less than fifteen sessions, were simply not possible within the frame of an operant conditioning model. Seeing no alternative to that model, he dismissed all of our reports from that point forward. In retrospect, this was a major blunder on his part, in that it entrenched a limited and flawed model of neurofeedback. Operant conditioning is involved, but it is not the whole story, or even the main one, in truly effective neurofeedback.
The observation that operant conditioning by itself isn’t actually very efficient training, even when it is done optimally, can also help to explain the lack of contrast between the experimental and sham cohorts in some of the published studies. When researchers arrange for an operant conditioning design, no doubt they do so quite rigorously, and thus place the emphasis on the discrete rewards exclusively. On that basis, at twenty sessions they are just getting going with the neurofeedback.
Most protocol-based neurofeedback training also involves an inhibit-based training component. This is not our focus on this occasion, but it should be noted that inhibit-based training is best understood in the associative learning model. The inhibits are simply notifications to the brain with respect to momentary excursions from good regulation, and the brain can do with that information what it will. In order to benefit, the brain has to detect a correlation of the inhibit signal with some aspect of its internal state. The notifications are non-prescriptive in character. Once again, the practitioner is a bystander in this process.
With the descent into the infra-low frequency regime with our training in 2005-6, all aspects of the original operant conditioning design were stripped away. There were no more thresholds; there were no more rewards. We were left with nothing but the process of associative learning operating on a continuous signal—and on the inhibits. This makes neurofeedback into a continuous, entirely self-referential, closed-loop process, one appropriately termed endogenous neuromodulation. This is a process of the brain engaging with information about itself to its own benefit. There is no clinician playing the role of ‘deus ex machina’ in the brain’s unfolding drama, subjecting the brain to a close-order drill.
The Imperative Role of Endogenous Neuromodulation
This calls for yet one more shift in our thinking. We are no longer dealing with a feedback process here, but rather with a feed-forward process. Where does the challenge lie, one might ask? What mobilizes change in the first place? The brain is organized as a prediction generator. It reacts to its own expectations, to the difference between the actual signal on the screen and what it had predicted for this signal. To recognize the signal is to assign meaning to it. That in turn has implications for the future. Thus the brain’s burden is to project the signal forward in time, and to react to the consequences. The brain is setting its own challenge. In the infra-low frequency region, where the signal is relatively bland, this process must necessarily be taking place at a very subtle level indeed. But it is with such subtlety that brain self-regulation must ultimately take place. And so we come, finally, to our forced conclusion:
No exogenous procedure, whether it be pharmacology or or stimulation or reinforcement-based neurofeedback of any kind, can rise to the level of subtlety, of comprehensive scope, of temporal precision and refinement of the brain’s regulatory regime. Only the brain itself can accomplish that objective, and we can only aid that process toward its requisite refinement by way of associative learning–purely by furnishing the brain relevant feedback on its own activity—with which it creates its own challenge. This should take place in a supportive, affirmative environment, one that is preferably devoid of other challenges and distractions. This is the process of endogenous neuromodulation, and that’s what we have been evolving for over thirty years.
In summary: The placebo model of neurofeedback is dead. This is not news. We have known this all along. What has not been generally recognized is that the operant conditioning model of neurofeedback has been on life support for many years as well. Although exogenous methods will continue to play their respective roles, our collective future lies largely with associative learning in general, and with endogenous neuromodulation–the brain reacting to a self-generated challenge–in particular. Give the brain any information about itself, and it will make sense out of it. The brain is the real hero of our story. We are merely uncovering its immense capacity to solve its own problems.