





The QEEG, Mechanisms, and EEG Dynamics
by Siegfried Othmer | May 19th, 2005 Jay writes on the QEEG-images list:
Jay writes on the QEEG-images list:
“Rather than looking at….. EEG/qEEG findings as “subtypes” of a specific disorder, we are now thinking of them as representative of phenotypical patterns seen with various genotypical and physiological presentations, and they speak to the heterogeneity of the pathophysiology of the various disorders. Phenotypes are an intermediate step between genetics and behavior, and they seem to predict the clinical intervention’s success.
The aberrant behaviors point to the neural networks that are not working, but not to the specific failure mode of the various systems involved. Behavior doesn’t predict the EEG (just the neural network), but the EEG data predicts behavior. The equation is not reversible. The pipe-dream of a behaviorally driven approach is thus foundationally and logically flawed, and will always have “outlier” or “subgroup” based problems.”
Jay Gunkelman
The original research to make the point convincingly that principal EEG categories cut across diagnostic boundaries was Emory and Suffin’s paper in the Clinical EEG journal back in 1995. That was a watershed. Since that time, that model has only been further reinforced with data that was not published simply because Suffin and Emory were chasing investor funding, but also because they saw the whole scheme of aligning EEG subtypes with pharmacological interventions as patentable, or at least proprietary. Their service is now commercially available.
People in our field were aware of this paper, but went on almost as if nothing had happened. Robert Gurnee, the Thompsons and Michael Linden continued to talk in terms of “subtypes” of ADHD, anxiety, depression, autism etc.. In each case, one would then be exposed to the same general patterns that had already been observed in all other cases. The principal EEG categories could be found in each of the diagnostic categories. So the whole idea of EEG subtypes of diagnostic categories has always been flawed, and should have been assigned to the scrap heap at least after May of 1995.
So Jack Johnstone, who collaborated with Suffin and Emory for many years, has now elaborated on their position with a model of “EEG phenotypes” that will hopefully lead to a more honest and comprehensive appraisal. It is really a different point of departure, one that is not based in the clinical categories at all. There is no necessary connection with any of the phenotypes with behavioral categories and psychiatric diagnoses. Well enough.
But now Jay goes on to say that even though behavior does not predict the EEG, the EEG does predict behavior. Hence, the “pipedream of a behaviorally driven approach is thus foundationally and logically flawed.” The EEG appears to be once again installed in some exalted position. I’m not quite sure what is meant here. Is he after us again? “Us” meaning those of us who aren’t buying his protocol recommendations? “Us” meaning those who don’t base protocols on the static EEG? Or is he simply saying that we are not in a position to go directly from diagnosis to protocol, that since the diagnosis cannot predict the EEG, it cannot possibly predict the protocol? Better then just to use the EEG to predict protocol.
In either event, we are ahead of Jay, not behind him. From day one we were using a single protocol irrespective of diagnosis. That’s the door we came in through. There was only one protocol as far as we were concerned, and it was Sterman’s. Sensorimotor rhythm reward-based training combined with high and low frequency inhibits. The diagnosis was secondary. You don’t have an “ADHD protocol” or a “depression protocol” if you have only one. Then as the protocol was fleshed out with right-side training as well as left, the training particularized to every client. Behavior was still not prescriptive for what was to be done, but certainly it became a guidepost to progress.
During all of this time, however, those who proposed diagnostically specific protocols, particularly those who did so based on EEG patterns, were deemed to be more scientific. That house of cards collapsed a long time ago, and it’s nice to have that finally acknowledged. So the logical chain of:
“Behavior” >> “Diagnosis” >> “EEG Subtype” >> “Neurofeedback Protocol” ain’t working.
Of course it does work in the sense that everything seems to work in neurofeedback. It is just clear by now that this model holds no special claim to the truth. The protocols work; it’s the labels that don’t work. They lack the implied specificity. All along the model had sufficient truth value to sustain it. Clearly such diagnoses as “Reactive Attachment Disorder,” “Post-traumatic Stress Disorder,” “Dissociative Identity Disorder,” and “Alexithymia” are very useful categorizations that will inform our approach to the client, but the neurofeedback approaches will be remarkably similar. For example, it will not be possible to review an actual training history and say, in retrospective judgment, that must have been a case of one of these diagnoses or another.
For us, the logical chain is that symptoms, or patterns of symptoms subsumed under a diagnostic category, are seen in terms of physiological mechanisms first and foremost. These mechanisms are confirmed or disconfirmed in the actual practice of neurofeedback. And in that practice, the EEG dynamics are what matters. So the logical flow for us is as follows:
“EEG Dynamics” >> “Neurofeedback” >> “Altered EEG Dynamics” >> “Improved Self-Regulation” >> “Altered Behavior” >> “Iterated protocol.”
Since we start with essentially a standard protocol with everyone, diagnosis is not determinative, nor is EEG subtype. The technique is not behaviorally driven at the outset (with only rare exceptions), but it is behaviorally responsive. The EEG dynamics are highly correlated with EEG statics, so these don’t usually have to be independently determined either. Moreover, it is the EEG dynamics that interest us more in the first place, and are presumably of greater import in self-regulation. Finally, all feedback operates on EEG dynamics irrespective of the guiding philosophy in protocol determination. So in the final analysis, EEG dynamics is all that is ever in play when it comes to neurofeedback.
So “behavior” becomes prescriptive for us at the outset only in a most general sense, and even then it is for us an outlier. Thus, for example, we might have a preference for right-side training for Attachment Disorder and other conditions involving major emotional disregulations. We will use a lower reward frequency as a starting point in the autistic spectrum. But the far more remarkable finding is that nearly all conditions that are responsive to neurofeedback are responsive to a single protocol. This observable, demonstrable, and ineluctable fact stands as an abiding indictment of all particularization approaches, i.e. all those that mandate particular approaches to particular conditions, no matter how derived. It is an indictment of all standard-setting wannabes, of the latter-day mound builders.
Exceptions to this do exist; first and foremost specific learning disabilities, as studied and remediated by Kirt Thornton using highly targeted approaches, determined through EEG measures under challenge conditions. But this just sharpens the distinction. Most conditions of interest to most psychologists do not fall into the category where a high degree of particularization is either necessary or even appropriate. A simple self-regulation strategy will do nicely.
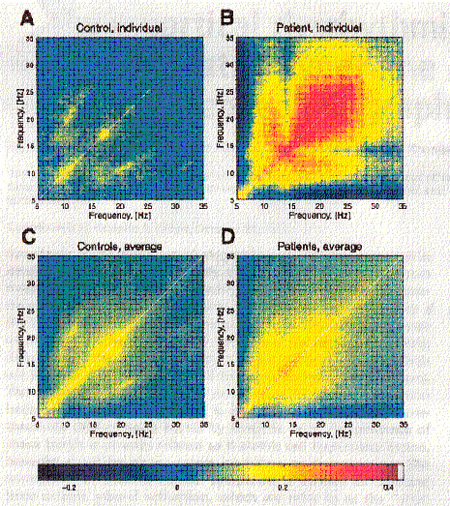
This discussion takes me back to Jay’s presentation last week at the ROSHI Conference. There he presented the figure from Rodolfo Llinas that shows excess coupling between different frequencies at the same scalp site. Such excess coupling characterizes a number of disparate conditions. A plot that shows the temporal relationships and correlations of different frequencies is known as a bispectrum. We reproduce the figure below. One can see that in the case of patients, as opposed to normals, there is a greater coupling or temporal correlation (time-locking), or comodulation, between different frequencies over a broad range of frequencies from theta up to the beta band.
Moreover, the essential character of the bispectrum is observable anywhere on the scalp. In consequence of this, Jay said “It does not matter just where on the head you put the electrode.” I perked up at this remarkable assertion coming from Jay, but to be fair to him, he only meant it with reference to the bispectrum, not to neurofeedback. But let’s take the logical flow just a little further in the direction in which it seems to want to go. What if a key mechanism of dysfunction does lie in the inappropriate temporal coupling of different frequencies, as Llinas’ data would indicate? Then how would you do neurofeedback?
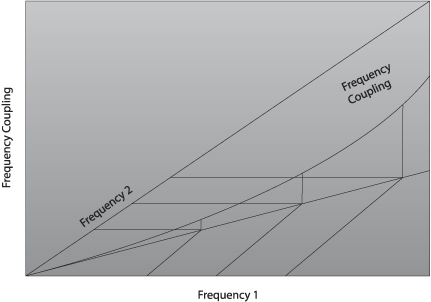
The coupling shown in Llinas is proportional to the spindle amplitudes of each of the constituent frequencies. This is sketched in the second Figure below. As we increase the amplitude of each component, therefore, the coupling increases nonlinearly, or geometrically as the product of the two constituents. An efficient way to reduce the coupling, therefore, is to reduce the amplitude of the constituents. That is what we do with the inhibit component of our protocols. On the nonlinear model, if the amplitude of each constituent is reduced by a factor of two, then the coupling between them will be reduced by a factor of four. Very efficient. And if we do this at one point on that scalp, is there anyone in the room who believes that we solve the problem only at that point on the scalp? Of course not. We are coupling into basic mechanisms of regulation. And if that is the case, then Jay’s statement that “It does not matter just where on the head you put the electrode” should hold true not only for the bispectrum, but also for the neurofeedback strategy that follows from it.
Curiously, we may have been shaped into doing the right thing (e.g., broadband inhibits) over the years even though we were not aware of this model until Llinas’ presentation in 1999. We have actually been using the figure from Llinas’ paper in our coursework now for the last five years to show how it might be possible to be so effective in neurofeedback with training at just a single site. But it remains true that some sites are more conveniently or efficiently trained than others. The best way to gain certainty in those regards is to do A/B comparisons in the most controlled situation possible, namely on the same client, and in the same timeframe. That is what we continually do. In this way our behavior is shaped toward the most effective techniques.
There is an analogy here to the feeding of the birds that we continue to do throughout the spring and summer at our town home. We would like to attract the birds, but we don’t want them to become dependent on us. (We don’t want to fatten up the squirrel too much either.) So we feed the birds episodically. Within hours, they find their way to the loot. And when the supply is exhausted, they stay away. So it is with us in the clinic. We gravitate toward the most effective approaches, and we linger there until the benefit has been plumbed.
And we never get into a defensive posture of: “I know this is the right protocol. I never heard of anything like that happening with neurofeedback! That couldn’t be the biofeedback….” The formulaic approach always leaves one with a blinkered perspective, bereft of options when non-classical effects are observed. There was a haste to be seen as scientifically grounded in the approach to neurofeedback, whether or not the science was well-founded. That’s like Exxon scouring the shores of Prince William Sound with high-pressure hot water after the Exxon Valdez incident. They knew they weren’t helping, but rather just compounding the damage of the oil with the damage of the hot water. But they had to be seen to be doing something for public consumption. Being under the gun just like Exxon, neurofeedback people badly needed to be seen to be doing something scrupulously scientific. The QEEG was the refuge. Its aura would sanctify the more questionable aspects of what we actually did. With feet on the ground now, there can be more honesty in the appraisals: It never did work for the field. With our new-found confidence, it is time to shed the inappropriate defenses.
Where does this leave us? Just about where we were before. Mechanisms-based or protocol-driven training applied adaptively and in a manner that is responsive to the client covers most of the bases that a mental health professional wants to cover, and does so most efficiently. Similarly, training that is purely based on responding to EEG dynamics (“The Blind Watchmaker”) also effects an efficient resolution to many conditions of interest to the mental health professional. And QEEG-driven training has a role to play as well. But in the emerging “phenotype” model of EEG subtypes, the implications for EEG training may well be indirect. For the conditions of interest to the mental health professional, we will go from
“EEG anomalies” >> “EEG Phenotype” >> EEG training protocol
rather than directly from
“EEG anomalies” >> EEG normalization training.
An electronic conversation with Val Brown:
Val Brown writes:
Sieg:
I have a thought experiment for you and, perhaps, a follow up question.
You use a single reward target with your current setup so it really does
make sense that it would be important to tune the center frequency of that
single reward so as to optimize the response of the client. That “tuning”
could theoretically be done via diagnostics, clinical assessment, QEEG,
response to training, etc but it certainly makes sense that such tuning
could be important to maximize the training response.
This need to “tune” the target is, quite likely, even more important given
the type of time-based IIR filtering that you use to “feed” that targeting
process, but that isn’t really the main point of the thought experiment.
Rather, the thought experiment concerns the restriction to a single “reward”
target that you continue to maintain despite considerable technological
advance since that design was developed. Why is that? Why continue to use
only a single “reward” target?
So, here’s the thought experiment. Do you think it’s possible to construct
an optimal — or simply “robust” enough set of targets — such that the
target set could usefully capture the range of variations through which you
fine tune your single “reward” target on an ad hoc basis? Can you imagine
that a set of concurrent targets could be developed and deployed such that
the fine tuning that you do currently would not be necessary?
val
Dear Val–
In broad brush, the diversity that is coming into the field of neurofeedback is to be welcomed. So there is no overriding urgency or even virtue in developing one technique that covers all of the bases, if that means giving up an advantage that attaches to particular techniques. It is indeed helpful to have techniques such as yours that don’t require much by way of clinical decision-making, but such techniques should be complemented by others that have “unique” advantages in one dimension or another. On the other hand, cross-fertilization of techniques is to be encouraged.
On that basis, I think it would be of interest to develop techniques that are as generic as possible, to be combined with techniques that have the advantage of specificity. The latter could be optional, but they should be available. So going to multiple targeting is the natural growth path for the field of EEG neurofeedback. This strengthens the part of the training that can be done autonomously at the level of the software. The clinician need not be involved at that level.
The stronger the technique, however, the more likely that the person may be shifted into uncomfortable states in the course of training. I had that experience just recently with the NCP, where I was left in a state of low arousal for a couple of days until I did the training that I was accustomed to doing with another system. That experience confirmed my expectation that arousal level could be significantly shifted in an NCP session. That being the case, one would like to have something in the armamentarium to serve as a rudder in the arousal domain. Otherwise the training is more engine than rudder, or more brawn than brain. The training does not appear by its nature to equilibrate at the best setpoint of function in the arousal domain.
We have learned that the brain can handle multiple challenges well, and that it can handle high dynamics well. So the ideal would be to shape the EEG via multiple targeting, but also to provide the rudder with a single additional reward that maintains traceability to what is happening in the brain with higher dynamics. If a single, narrowly-targeted reward is used for an extended period of time, that target has to be chosen carefully, and the person monitored for good outcome. The compensating benefit is that the person’s arousal state can be fine-tuned at will.
The lower temporal dynamics of the multiple targeting can be accomplished either with frequency conversion into the spectral domain using transform techniques, or it can be accomplished with digital filtering. On the other hand, the narrow targeting of a single reward band is best accomplished with digital filtering (because phase information needs to be preserved). That being the case, it lies close to hand to simply do the entire analysis using digital filtering as opposed to using transform techniques in combination with digital filtering.
You may wish to regard the addition of a narrow reward target as optional, and it may in fact be optional. But the joint offering would enlarge the “footprint” of your approach.
Our perspectives differ in that you see our approach as representing only a single reward target when in fact you offer many. We see our approach as offering a different challenge to the brain entirely, one involving high dynamics, and in that regard the brain probably can’t handle too many at a time. I tend to see your box targeting as acting preferentially on excursions to large amplitude rather than to low, unless offsets are used. You seem to be tending away from the use of offsets across the board. This means that in our traditional terminology, the boxes serve much more as inhibits than as rewards.
Also, in your conventional deployment of your technique, the person is getting information only when the “system” goes out of bounds with respect to the box targets. In our kind of targeting, the brain is getting continuous feedback. This means a higher duty cycle for feedback information, which at least holds the potential of greater training efficiency.
The two approaches are complementary also in the following way: By emphasizing variability training, or using “rate of change” within a particular band as the criterion for the withholding of a reward, the current NCP approach favors training what we call the “instabilities,” the sudden, apparently unprovoked changes in brain state. Now as it happens, that is also the particular strength of the inter-hemispheric training. But the latter also offers the advantage of “vernier” control of state so that we access those issues that are matters of “set-point” or “thermostatic” control–e.g. the fine-tuning of motor excitability, of autonomic balancing, and of sensory excitability.
We do acknowledge that our current fascination with inter-hemispheric training will likely be just a stepping-stone to full-bore two-channel training. The multiple-targeting strategy really comes into its own with two channels. So that is where a convergence of our approaches is likely to take place.
This entry was posted on Thursday, May 19th, 2005 at 7:53 pm and is filed under Uncategorized. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.